
Operationalizing Engineering Statistics: The Industry Expert’s Take
Learn how Ascend and Dow use Seeq to enable process improvement and enhance quality control.
Process manufacturing companies are using Seeq to connect to their quality and process data, create and automate statistical analyses like control charts and process capability, and use near-real-time reporting to generate actionable insights. In a recent webinar series, Seeq spoke to Brian Scallan, Director of Continuous Improvement from Ascend Performance Materials, and Jeff Crain, Technology Manager from The Dow Chemical Company, about how they are using Seeq to enable process improvement and how it is enabling efforts to enhance quality control.
Episode 1: Enabling Process Improvement
The Role of Digital Transformation in Enabling Process Improvement
Brian shared a story about a plant that recently went through a process improvement journey. This plant was using an old implementation of SPC, governed mostly by administrative controls, and these controls had started to fail. The process capability had drifted to the outer edges of the specifications, which meant normal variation was causing quality violations, resulting in hundreds of thousands of pounds of quarantined material. To address the issue, he emphasized that it was time to take a step back and do things differently, moving to a modern, more robust solution. By integrating Seeq into this workflow, Ascend established live connections with data sources, enabled knowledge capture and collaboration, and empowered subject matter experts (SMEs) with the right analytics tools. On Ascend’s use of Seeq for near-real-time SPC quality monitoring, Brian comments, “We reduced the material we were having to quarantine monthly by two orders of magnitude to what we are seeing today.”
“We reduced the material we were having to quarantine monthly by two orders of magnitude to what we are seeing today.” – Brian Scallan, Ascend
Driving Up Process Capability with Visible Metrics
With control of the plant regained, it was time to explore the next steps in process optimization. Brian comments, “You don’t get credit for keeping process control”, rather it’s more of an operational expectation. The next opportunity is to drive down variability and increase process capability – that’s where the value is. This is where active process monitoring comes in – what gets measured gets done. To drive value, an engineer at the Ascend plant used Seeq Organizer to create dashboards with near-real-time calculations, charts, and graphs that are shared with operators, management, and other engineers. Making statistical process control and process capability visible in these dashboards enables data-driven decision-making to know when to intervene versus leaving the process alone, which helps drive up process capability.
“Having that data live, and no longer stuck on somebody’s laptop, and anybody can see–whether it’s a production manager, an operator, an engineer, whoever. Giving them that information live is very powerful.” – Brian Scallan, Ascend
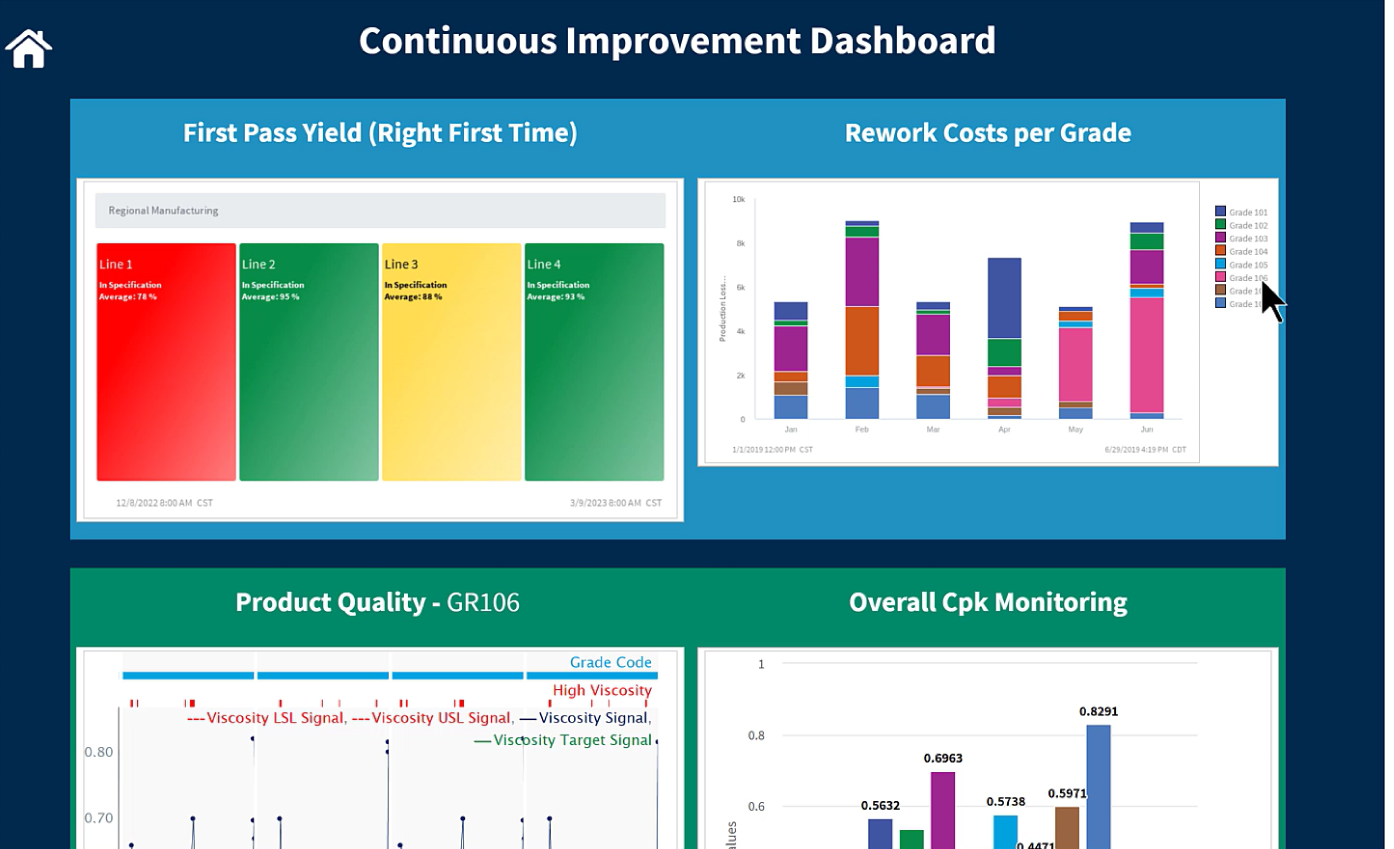
The difference makers:
- Connected Data Sources – The previous SPC implementation relied on a spreadsheet-oriented workflow: query the data historian, dump the data into a spreadsheet, and spend a couple of days contextualizing the data. Brian says, “From an SPC and process capability standpoint, the move into a more modern implementation with Seeq means the data is connected all the time and analyses automatically update as new data comes in.”
- Purpose-built Analytical Tools – In the plant’s process improvement journey, eliminating special cause variation is the first step, but the harder step is reducing normal variation to drive up process capability. This requires targeted analysis and SME expertise to dig into many variables and identify improvement opportunities. Using Seeq’s purpose-built tools is a huge time and opportunity cost, SMEs are identifying time periods of interest and jumping into the analysis phase more quickly. Brian comments, “One way to look at an engineer’s time…are you generating 5x the value of your salary, and they can’t do that if we don’t give them the right tools.”
Episode 2: Enhancing Quality Control to Improve Product Consistency
SPC, SQC, and Their Value in Process Manufacturing
SPC and SQC are sometimes used interchangeably in manufacturing, with the delineator being the underlying data being analyzed. SPC is focused on measuring and analyzing process inputs, temperature or pressure variations, for example, while SQC is focused on measuring and analyzing process outputs, like product characteristics.
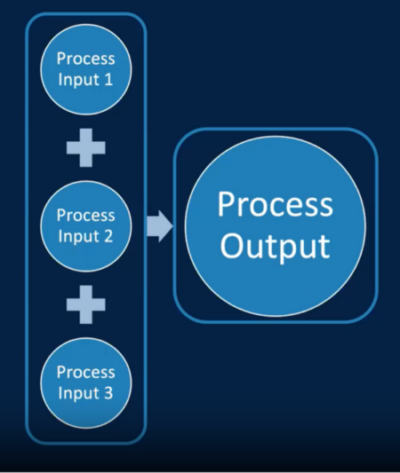
With SQC, the focus is not only on whether the product output is within specification but also if it is consistent. Jeff states, “Detecting unusual product is foundational if you are a manufacturer. [By using SQC] we are avoiding a dangerous assumption that specifications capture customer expectations.” This attitude is essential for next-level supplier performance, can drive upstream process improvements, and enables product differentiation in the marketplace. However, it also comes with cons. SQC is more reactive, where discovery and corrective action come after production, reworking or downgrading “in-spec” but inconsistent product impacts the bottom line, and, in commodity markets, the primary volume driver is price, not consistency.
“Detecting unusual product is foundational if you are a manufacturer. [By using SQC] we are avoiding a dangerous assumption that specifications capture customer expectations.” – Jeff Crain, Dow
The Dilemma: Conformance vs. Consistency
Jeff gives his thoughts on how to approach the dilemma between conformance to specification vs. consistency. He explains if there is no history of customer complaints due to consistency, it is hard to make a case to quarantine product. If consistency is not important to the customer, then release it. But there are plenty of examples where inconsistent product is a problem for the customer. In this case, they must consider migrating the culture from a conformance-to-specification mentality to a consistency mentality, which is never easy. But when your customers are expecting consistent product, and you are not delivering it, you must drive culture change.
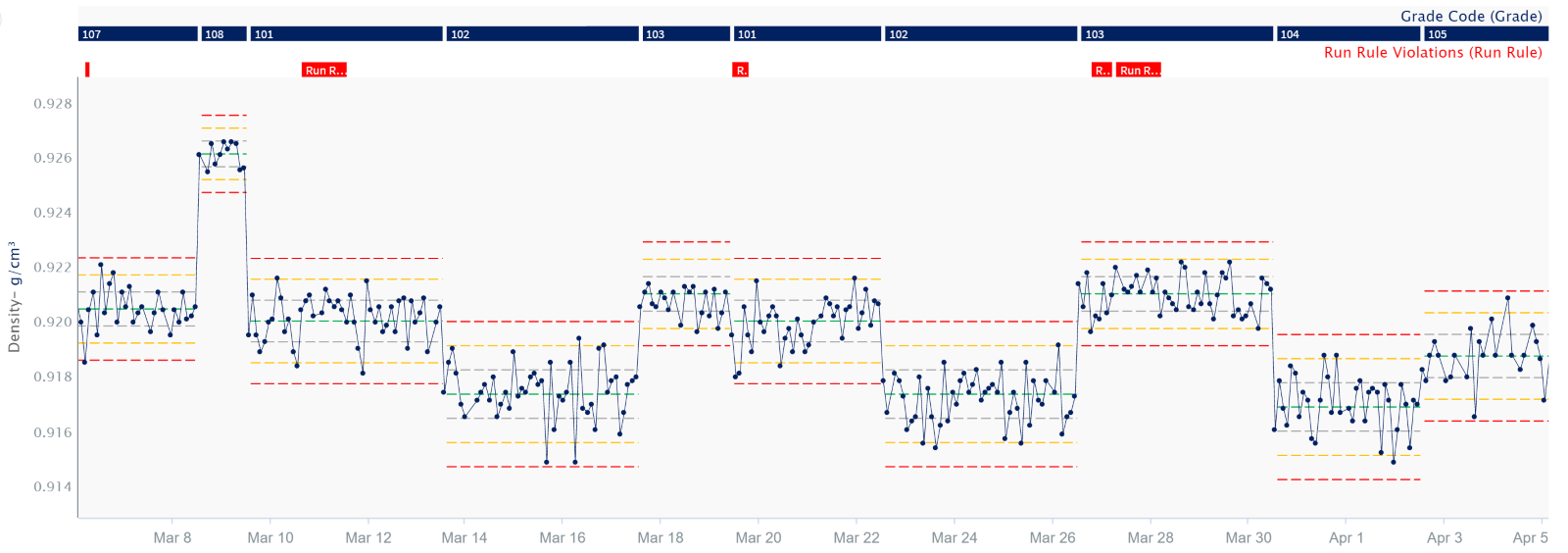
The Vision for SQC at Dow and How Seeq Fills the Gaps
Seeq is new to Dow. The long-term vision is to offer Seeq as an enterprise-level solution that will enable the end users to analyze and make decisions based on those analytics with the minimum possible expert support. Jeff says, “We’re moving towards more self-service solutions, and that’s an application where Seeq really shines.” The keys to a good SQC program are scalability, automation, visibility, and self-service. This is where Seeq comes in. Seeq connect to many different data sources making it easily scalable as an enterprise-wide solution, empowers end-users with easy-to-use analytics tools, automatically connects to new data as its generated, and ensures users can easily visualize and consume near-real-time data to quickly make data-driven decisions.
“The vision is to offer an enterprise-level solution that will enable end-users to analyze and make decisions based on those analytics with the minimum possible amount of expert support… We’re moving towards more self-service solutions, and that’s an application where Seeq really shines.” – Jeff Crain, Dow
Watch the Webinars Today
Interested in learning more about how Ascend and Dow are using Seeq to enable process improvement and how it is enabling efforts to enhance quality control? View the full webinar to see the technology in action.
- Episode 1: Enabling Process Improvement
- Episode 2: Enhancing Quality Control to Improve Product Consistency
And if you are ready to discuss how Seeq can improve your operations, please contact us to speak with one of our industry experts and schedule a demo today.